An IO monad for cats
by Daniel Spiewak on May 02, 2017
technical
Haskell is a pure language. Every Haskell expression is referentially transparent, meaning that you can substitute that expression with its evaluated result without changing the program. Or, put into code:
-- this program
f expr expr -- apply function f to arguments expr, expr
-- is equivalent to this one, which factors out `expr`
let
x = expr -- introduce a new variable `x` with the value of `expr`
in
f x x
And this is true for all expressions e, and all functions f. These could be complex expressions which describe ways of manipulating network channels or window buffers, or something trivial like a numeric literal. You can always substitute the expression with its value.
This is not true in Scala, simply because Scala allows unrestricted side-effects. Unlike Haskell, Scala puts no limitations on where and when we can use things like mutable state (vars) or evaluated external effects like println or launchTheMissiles. Since there are no restrictions on where and when we can do evil, the Scala equivalent to the above just doesn’t work:
f(e, e)
// isn't really equivalent to!
val x = e
f(x, x)
The reason it isn’t equivalent comes from the different sorts of expressions that we could find in e. For example, what if e is println("hi!"). If we make that substitution, our snippet looks like the following:
f(println("hi"), println("hi"))
// isn't really equivalent to!
val x = println("hi")
f(x, x)
Clearly these are not the same two programs. The first prints "hi" twice, while the second only prints it once. This is a violation of referential transparency, and it’s why we sometimes say that Scala is an impure language. Any expression which is not referentially transparent must contain side-effects, by definition.
Now of course, we found this problem by using a side-effecting function: namely, println. Haskell clearly has the ability to print to standard output, so how does it avoid this issue? If we build the same program in Haskell, can we violate referential transparency?
f (putStrLn "hi") (putStrLn "hi")
-- is equivalent to
let x = putStrLn "hi" in f x x
As it turns out, this is still referentially transparent! These two programs still have the same meaning. This is possible only because neither program actually prints anything!
In Haskell, effects are treated as first-class values. The putStrLn function doesn’t print to standard out, it returns a value (of type IO ()) which describes how to print to standard out, but stops short of actually doing it. These sorts of values can be composed using the monadic operators (in Scala, flatMap and pure), allowing Haskell programmers to build up expressions composed of sequences of dependent effects, all of which are merely descriptions of the side-effects which will eventually be performed by the runtime. Ultimately, the description which comprises your whole program is the return result from the main function. The Haskell runtime runs the main function to get this description of all your effects, and then runs the effects per your instructions.
This is kind of a clever trick. It allows Haskell to simultaneously be pure and still have excellent support for manipulating effects and interacting with the “real world”. But why is it relevant to Scala? After all, Scala is an impure language. We don’t need to go through this complex rigmarole of describing our effects and composing those descriptions; the language lets us just do it! So why wouldn’t we just, you know, evaluate the effects that we need evaluated?
The answer is that we want to reason about where and when our effects are evaluated. And of course, we want to be able to leverage laws and abstractions which assume equational semantics for expressions (i.e. referential transparency). Cats is full of these sorts of abstractions, and cats-laws provides a vast set of laws which describe them. But all of these abstractions and all of these laws break down the moment you introduce some sort of side-effecting expression. Because, much like our referential transparency example from earlier, these abstractions assume that you can substitute expressions with their evaluated results, and that’s just not true in the presence of side-effects.
What we need is a data type which allows us to encapsulate Scala-style side-effects in the form of a pure value, on which referential transparency holds and which we can compose using other well-defined abstractions, such as Monad. Scalaz defines two such data types which meet these criteria: scalaz.effect.IO and scalaz.concurrent.Task. But in practice, nearly everyone uses Task instead of IO because of its support for asynchronous effects.
Cats does not define any such abstraction, and what’s worse is the cats ecosystem also doesn’t really provide any such abstraction. There are two Task implementations that are relatively commonly used with cats – namely, monix.eval.Task and fs2.Task – but these are not part of cats per se, nor are they deeply integrated into its abstraction hierarchy. Additionally, the proliferation of broadly equivalent options has led to confusion in the ecosystem, with middleware authors often forced to choose a solution for their end-users, and end-users uncertain as to which choice is “right”.
Introducing cats-effect
The cats-effect project aims to change all of that. The goal of cats-effect is to provide an “easy default” IO type for the cats ecosystem, deeply integrated with cats-core, with all of the features and performance that are required for real world production use. Additionally, cats-effect defines a set of abstractions in the form of several typeclasses which describe what it means to be a pure effect type. These abstractions are extremely useful both in enabling MTL-style program composition and to ensure that other pre-existing Task implementations remain first-class citizens of the ecosystem. IO does not overshadow monix.eval.Task or fs2.Task; it complements them by providing a set of abstractions and laws which allow users to write safe, parametric code which supports each of them equally.
One important sidebar here: cats-effect does not provide any concurrency primitives. scalaz.concurrent.Task and monix.eval.Task are both notable for providing functions such as both, which takes two Tasks and runs them in parallel, returning a Task of a tuple of the results. The cats.effect.IO type does not provide any such function, and while it would be possible to define such a function (and others like it!), we strongly encourage users to instead consider full-on streaming frameworks such as fs2 or Monix for their concurrency needs, as these frameworks are able to provide a much sounder foundation for such functions. See here for a rough outline of why this is. Also note that some Task implementations, such as Monix’s, can and do provide parallelism on a sound foundation by enriching their internal algebraic structures. Thus, monix.eval.Task is actually quite different from cats.effect.IO, despite having a similar core set of operations.
Enough Talk…
What does this look like in practice? Well, ideally, as convenient as possible! Let’s look at our println example:
def putStrLn(line: String): IO[Unit] =
IO { println(line) }
f(putStrLn("hi!"), putStrLn("hi!"))
// is equivalent to
val x = putStrLn("hi!")
f(x, x)
Great! We can write Haskell fanfic in Scala. 😛
The notable element here is the use of the IO.apply constructor to wrap the println effect in a pure IO value. This pattern can be applied to any side-effect. You can think of this sort of like an FFI that converts impure code (like println) into pure code (like putStrLn). The goal of this API was to be as simple and straightforward as possible. If you have a curly brace block of impure side-effecting code, you can wrap it in a composable and pure abstraction by just adding two characters: IO. You can wrap arbitrarily large or small blocks of code, potentially involving complex allocations, JNI calls, resource semantics, etc; but it is generally considered a best practice to wrap side-effects into the smallest composable units that make sense and do all of your sequentialization using flatMap and for-comprehensions.
For example, here’s a program that performs some simple user interaction in the shell:
import cats.effect.IO
val program = for {
_ <- IO { println("Welcome to Scala! What's your name?") }
name <- IO { Console.readLine }
_ <- IO { println(s"Well hello, $name!") }
} yield ()
We could have just as easily written this program in the following way:
val program = IO {
println("Welcome to Scala! What's your name?")
val name = Console.readLine
println(s"Well hello, $name!")
}
But this gives us less flexibility for composition. Remember that even though program is a pure and referentially transparent value, its definition is not, which is to say that IO { expr } is not the same as val x = expr; IO { x }. Anything inside the IO { … } block is not referentially transparent, and so should be treated with extreme care and suspicion. The less of our program we have inside these blocks, the better!
As a sidebar that is actually kinda cool, we can implement a readString IO action that wraps Console.readLine as a val!
val readString = IO { Console.readLine }
This is totally valid! We don’t need to worry about the difference between def and val anymore, because IO is referentially transparent. So you use def when you need parameters, and you use val when you don’t, and you don’t have to think about evaluation semantics. No more subtle bugs caused by accidentally memoizing your effects!
Of course, if program is referentially transparent, then clearly repeated values of program cannot possibly run the effects it represents multiple times. For example:
program
program
program
// must be the same as!
program
If this weren’t the case, then we would be in trouble when trying to construct examples like the Haskell one from earlier. But there is an implication here that is quite profound: IO cannot eagerly evaluate its effects, and similarly cannot memoize its results! If IO were to eagerly evaluate or to memoize, then we could no longer replace references to the expression with the expression itself, since that would result in a different IO instance to be evaluated separately.
This is precisely why scala.concurrent.Future is not a suitable type for encapsulating effects in this way: constructing a Future that will eventually side-effect is itself a side-effect! Future evaluates eagerly (sort of, see below) and memoizes its results, meaning that a println inside of a given Future will only evaluate once, even if the Future is sequenced multiple times. This in turn means that val x = Future(...); f(x, x) is not the same program as f(Future(...), Future(...)), which is the very definition of a violation of referential transparency.
Coming back to IO… If program does not evaluate eagerly, then clearly there must be some mechanism for asking it to evaluate. After all, Scala is not like Haskell: we don’t return a value of type IO[Unit] from our main function. IO provides an FFI of sorts for wrapping side-effecting code into pure IO values, so it must also provide an FFI for going in the opposite direction: taking a pure IO value and evaluating its constituent actions as side-effects.
program.unsafeRunSync() // uh oh!
This function is called unsafeRunSync(). Given an IO[A], the unsafeRunSync() function will give you a value of type A. You should only call this function once, ideally at the very end of your program! (i.e. in your main function) Just as with IO.apply, any expression involving unsafeRunSync() is not referentially transparent. For example:
program.unsafeRunSync()
program.unsafeRunSync()
The above will run program twice. So clearly, referential transparency is out the window whenever we do this, and we cannot expect the normal laws and abstractions to remain sound in the presence of this function.
A sidebar on Future’s eager evaluation
As Viktor Klang is fond of pointing out, Future doesn’t need to evaluate eagerly. It is possible to define an ExecutionContext in which Future defers its evaluation until some indefinitely later point. However, this is not the default mode of operation for 99% of all Futures ever constructed; most people just use ExecutionContext.global and leave it at that. Additionally, if someone hands me an arbitrary Future, perhaps as a return value from a function, I really have no idea whether or not that Future is secretly running without my consent. In other words, the referential transparency (or lack thereof) of functions that I write using Future is dependent on the runtime configuration of some other function which is hidden from me. That’s not referential transparency anymore. Because we cannot be certain that Future is deferring its evaluation, we must defensively assume that it is not.
This, in a nutshell, is precisely why Future is not appropriate for functional programming. IO provides a pair of functions (fromFuture and unsafeToFuture) for interacting with Future-using APIs, but in general, you should try to stick with IO as much as possible when manipulating effects.
Asynchrony and the JVM
Scala runs on three platforms: the JVM, JavaScript and LLVM. For the moment, we’ll just focus on the first two. The JVM has support for multiple threads, but those threads are native (i.e. kernel) threads, meaning that they are relatively expensive to create and maintain in the runtime. They are a very limited resource, sort of like file handles or heap space, and you can’t just write programs which require an unbounded number of them. The exact upper bound on the JVM varies from platform to platform, and varies considerably depending on your GC configuration, but a general rule of thumb is “a few thousand”, where “few” is a small number. In practice, you’re going to want far less threads than that if you want to avoid thrashing your GC, and most applications will divide themselves into a bounded “main” thread pool (usually bounded to exactly the number of CPUs) on which all CPU-bound tasks are performed and most of the program runs, as well as a set of unbounded “blocking” thread pools on which blocking IO actions (such as anything in java.io) are run. When you add NIO worker pools into the mix, the final number of threads in a practical production service is usually around 30-40 on an 8 CPU machine, growing roughly linearly as you add CPUs. Clearly, this is not a very large number.
On JavaScript runtimes (such as node or in the browser), the situation is even worse: you have exactly one thread! JavaScript simply doesn’t have multi-threading in any (real) form, and so it’s like the JVM situation, but 30-40x more constraining.
For this reason, we need to be very careful when writing Scala to treat threads as an extremely scarce resource. Blocking threads (using mechanisms such as wait, join or CountDownLatch) should be considered absolutely anathema, since it selfishly wastes a very finite and very critical resource, leading to thread starvation and deadlocks.
This is very different from how things are in Haskell though! The Haskell runtime is implemented around the concept of green threads, which is to say, emulated concurrency by means of a runtime dispatch lock. Haskell basically creates a global bounded thread pool in the runtime with the same number of threads as your machine has CPUs. On top of that pool, it runs dispatch trampolines that schedule and evict expression evaluation, effectively emulating an arbitrarily large number of “fake” threads atop a small fixed set of “real” threads. So when you write code in Haskell, you generally just assume that threads are extremely cheap and you can have as many of them as you want. Under these circumstances, blocking a thread is not really a big deal (as long as you don’t do it in FFI native code), so there’s no reason to go out of your way to avoid it in abstractions like IO.
This presents a bit of a dilemma for cats-effect: we want to provide a practical pure abstraction for encapsulating effects, but we need to run on the JVM and on JavaScript which means we need to provide a way to avoid thread blocking. So, the IO implementation in cats-effect is going to necessarily end up looking very, very different from the one in Haskell, providing a very different set of operations.
Specifically, cats.effect.IO provides an additional constructor, async, which allows the construction of IO instances from callback-driven APIs. This is generally referred to as “asynchronous” control flow, as opposed to “synchronous” control flow (represented by the apply constructor). To see how this works, we’re going to need a bit of setup.
Consider the following somewhat-realistic NIO API (translated to Scala):
trait Response[T] {
def onError(t: Throwable): Unit
def onSuccess(t: T): Unit
}
// defined trait Response
trait Channel {
def sendBytes(chunk: Array[Byte], handler: Response[Unit]): Unit
def receiveBytes(handler: Response[Array[Byte]]): Unit
}
// defined trait Channel
This is an asynchronous API. Neither of the functions sendBytes or receiveBytes attempt to block on completion. Instead, they schedule their operations via some underlying mechanism. This interface could be implemented on top of java.io (which is a synchronous API) through the use of an internal thread pool, but most NIO implementations are actually going to delegate their scheduling all the way down to the kernel layer, avoiding the consumption of a precious thread while waiting for the underlying IO – which, in the case of network sockets, may be a very long wait indeed!
Wrapping this sort of API in a referentially transparent and uniform fashion is a very important feature of IO, precisely because of Scala’s underlying platform constraints. Clearly, sendBytes and receiveBytes both represent side-effects, but they’re different than println and readLine in that they don’t produce their results in a sequentially returned value. Instead, they take a callback, Response, which will eventually be notified (likely on some other thread!) when the result is available. The IO.async constructor is designed for precisely these situations:
def send(c: Channel, chunk: Array[Byte]): IO[Unit] = {
IO async { cb =>
c.sendBytes(chunk, new Response[Unit] {
def onError(t: Throwable) = cb(Left(t))
def onSuccess(v: Unit) = cb(Right(()))
})
}
}
// send: (c: Channel, chunk: Array[Byte])cats.effect.IO[Unit]
def receive(c: Channel): IO[Array[Byte]] = {
IO async { cb =>
c.receiveBytes(new Response[Array[Byte]] {
def onError(t: Throwable) = cb(Left(t))
def onSuccess(chunk: Array[Byte]) = cb(Right(chunk))
})
}
}
// receive: (c: Channel)cats.effect.IO[Array[Byte]]
Obviously, this is a little more daunting than the println examples from earlier, but that’s mostly the fault of the anonymous inner class syntactic ceremony. The IO interaction is actually quite simple!
The async constructor takes a function which is handed a callback (represented above by cb in both cases). This callback is itself a function of type Either[Throwable, A] => Unit, where A is the type produced by the IO. So when our Response comes back as onSuccess in the send example, we invoke the callback with a Right(()) since we’re trying to produce an IO[Unit]. When the Response comes back as onSuccess in the receive example, we invoke the callback with Right(chunk), since the IO produces an Array[Byte].
Now remember, IO is still a monad, and IO values constructed with async are perfectly capable of all of the things that “normal”, synchronous IO values are, which means that you can use these values inside for-comprehensions and other conventional composition! This is incredibly, unbelievably nice in practice, because it takes your complex, nested, callback-driven code and flattens it into simple, easy-to-read sequential composition. For example:
val c: Channel = null // pretend this is an actual channel
for {
_ <- send(c, "SYN".getBytes)
response <- receive(c)
_ <- if (response == "ACK".getBytes) // pretend == works on Array[Byte]
IO { println("found the guy!") }
else
IO { println("no idea what happened, but it wasn't good") }
} yield ()
This is kind of amazing. There’s no thread blocking at all in the above (other than the println blocking on standard output). The receive could take quite a long time to come back to us, and our thread is free to do other things in the interim. Everything is driven by callbacks under the surface, and asynchronous actions can be manipulated just as easily as synchronous ones.
Of course, this is an even bigger win on JavaScript, where nearly everything is callback-based, and gigantic, deeply nested chunks of code are not unusual. IO allows you to flatten those deeply nested chunks of code into a nice, clean, linear and sequential formulation.
Thread Shifting
Now there is a caveat here. When our Response handler is invoked by Channel, it is very likely that the callback will be run on a thread which is part of a different thread pool than our main program. Remember from earlier where I described how most well-designed Java services are organized:
- A bounded thread pool set to num CPUs in size for any non-IO actions
- A set of unbounded thread pools for blocking IO
- Some bounded internal thread worker pools for NIO polling
We definitely want to run nearly everything on that first pool (which is probably ExecutionContext.global), but we’re probably going to receive the Response callback on one of the third pools. So how can we force the rest of our program (including those printlns) back onto the main pool?
The answer is the shift function.
import scala.concurrent._
implicit val ec = ExecutionContext.global
for {
_ <- send(c, "SYN".getBytes)
response <- receive(c).shift // there's no place like home!
_ <- if (response == "ACK".getBytes) // pretend == works on Array[Byte]
IO { println("found the guy!") }
else
IO { println("no idea what happened, but it wasn't good") }
} yield ()
shift’s functionality is a little complicated, but generally speaking, you should think of it as a “force this IO onto this other thread pool” function. Of course, when receive executes, most of its work isn’t done on any thread at all (since it is simply registering a hook with the kernel), and so that work isn’t thread shifted to any pool, main or otherwise. But when receive gets back to us with the network response, the callback will be handled and then immediately thread-shifted back onto the main pool, which is passed implicitly as a parameter to shift (you can also pass this explicitly if you like). This thread-shifting means that all of the subsequent actions within the for-comprehension – which is to say, the continuation of receive(c) – will be run on the ec thread pool, rather than whatever worker pool is used internally by Channel. This is an extremely common use-case in practice, and IO attempts to make it as straightforward as possible.
Another possible application of thread shifting is ensuring that a blocking IO action is relocated from the main, CPU-bound thread pool onto one of the pools designated for blocking IO. An example of this would be any interaction with java.io:
import java.io.{BufferedReader, FileReader}
// import java.io.{BufferedReader, FileReader}
def readLines(name: String): IO[Vector[String]] = IO {
val reader = new BufferedReader(new FileReader(name))
var back: Vector[String] = Vector.empty
try {
var line: String = null
do {
line = reader.readLine()
back :+ line
} while (line != null)
} finally {
reader.close()
}
back
}
// readLines: (name: String)cats.effect.IO[Vector[String]]
for {
_ <- IO { println("Name, pls.") }
name <- IO { Console.readLine }
lines <- readLines("names.txt")
_ <- if (lines.contains(name))
IO { println("You're on the list, boss.") }
else
IO { println("Get outa here!") }
} yield ()
Clearly, readLines is blocking the underlying thread while it waits for the disk to return the file contents to us, and for a large file, we might be blocking the thread for quite a long time! Now if we’re treating our thread pools with respect (as described above), then we probably have a pair of ExecutionContext(s) sitting around in our code somewhere:
import java.util.concurrent.Executors
implicit val Main = ExecutionContext.global
val BlockingFileIO = ExecutionContext.fromExecutor(Executors.newCachedThreadPool())
We want to ensure that readLines runs on the BlockingFileIO pool, while everything else in the for-comprehension runs on Main. How can we achieve this?
With shift!
for {
_ <- IO { println("Name, pls.") }
name <- IO { Console.readLine }
lines <- readLines("names.txt").shift(BlockingFileIO).shift(Main)
_ <- if (lines.contains(name))
IO { println("You're on the list, boss.") }
else
IO { println("Get outa here!") }
} yield ()
Now we’re definitely in bizarro land. Two calls to shift, one after the other? Let’s break this apart:
readLines("names.txt").shift(BlockingFileIO)
One of the functions of shift is to take the IO action it is given and relocate that action onto the given thread pool. In the case of receive, this component of shift was meaningless since receive didn’t use a thread under the surface (it was asynchronous!). However, readLines does use a thread under the surface (hint: it was constructed with IO.apply rather than IO.async), and so that work will be relocated onto the BlockingFileIO pool by the above expression.
Additionally, the continuation of this work will also be relocated onto the BlockingFileIO pool, and that’s definitely not what we want. The evaluation of the contains function is definitely CPU-bound, and should be run on the Main pool. So we need to shift a second time, but only the continuation of the readLines action, not readLines itself. As it turns out, we can achieve this just by adding the second shift call:
readLines("names.txt").shift(BlockingFileIO).shift(Main)
Now, readLines will be run on the BlockingFileIO pool, but the continuation of readLines (namely, everything that follows it in the for-comprehension) will be run on Main. This works because shift creates an asynchronous IO that schedules the target action on the given thread pool and invokes its continuation from a callback. The ExecutionContext#execute function should give you an idea of how this works. This means that the result of the first shift is an IO constructed with async, and cannot itself be thread-shifted (unlike an IO constructed with apply), but its continuation can be thread-shifted, which is exactly what happens.
This sort of double-shift idiom is very common in production service code that makes use of legacy blocking IO libraries such as java.io.
Synchronous vs Asynchronous Execution
Speaking of asynchrony, readers who have been looking ahead in the class syllabus probably realized that the type signature of unsafeRunSync() is more than a little suspicious. Specifically, it promises to give us an A immediately given an IO[A]; but if that IO[A] is an asynchronous action invoked with a callback, how can it achieve this promise?
The answer is that it blocks a thread. (gasp!!!) Under the surface, a CountDownLatch is used to block the calling thread whenever an IO is encountered that was constructed with IO.async. Functionally, this is very similar to the Await.result function in scala.concurrent, and it is just as dangerous. Additionally, it clearly cannot possibly work on JavaScript, since you only have one thread to block! If you try to call unsafeRunSync() on JavaScript with an underlying IO.async, it will just throw an exception rather than deadlock your application.
This is not such a great state of affairs. I mean, it works if unsafeRunSync() is being run in test code, or as the last line of your main function, but sometimes we need to interact with legacy code or with Java APIs that weren’t designed for purity. Sometimes, we just have to evaluate our IO actions before “the end of the world”, and when we do that, we don’t want to block any of our precious threads.
So IO provides an additional function: unsafeRunAsync. This function takes a callback (of type Either[Throwable, A] => Unit) which it will run when (and if) the IO[A] completes its execution. As the name implies, this function is also not referentially transparent, but unlike unsafeRunSync(), it will not block a thread.
As a sidebar that will be important in a few paragraphs, IO also defines a safe function called runAsync which has a very similar signature to unsafeRunAsync, except it returns an IO[Unit]. The IO[Unit] which is returned from this function will not block if you call unsafeRunAsync(). In other words, it is always safe to call unsafeRunSync() on the results of runAsync, even on JavaScript.
Another way to look at this is in terms of unsafeRunAsync. You can define unsafeRunAsync in terms of runAsync and unsafeRunSync():
def unsafeRunAsync[A](ioa: IO[A])(cb: Either[Throwable, A] => Unit): Unit =
ioa.runAsync(e => IO { cb(e) }).unsafeRunSync()
// unsafeRunAsync: [A](ioa: cats.effect.IO[A])(cb: Either[Throwable,A] => Unit)Unit
This isn’t the actual definition, but it would be a valid one, and it would run correctly on every platform.
Abstraction and Lawfulness
As mentioned earlier (about 10000 words ago…), the cats-effect project not only provides a concrete IO type with a lot of nice features, it also provides a set of abstractions characterized by typeclasses and associated laws. These abstractions collectively define what it means to be a type which encapsulates side-effects in a pure fashion, and they are implemented by IO as well as several other types (including fs2.Task and monix.eval.Task). The hierarchy looks like this:
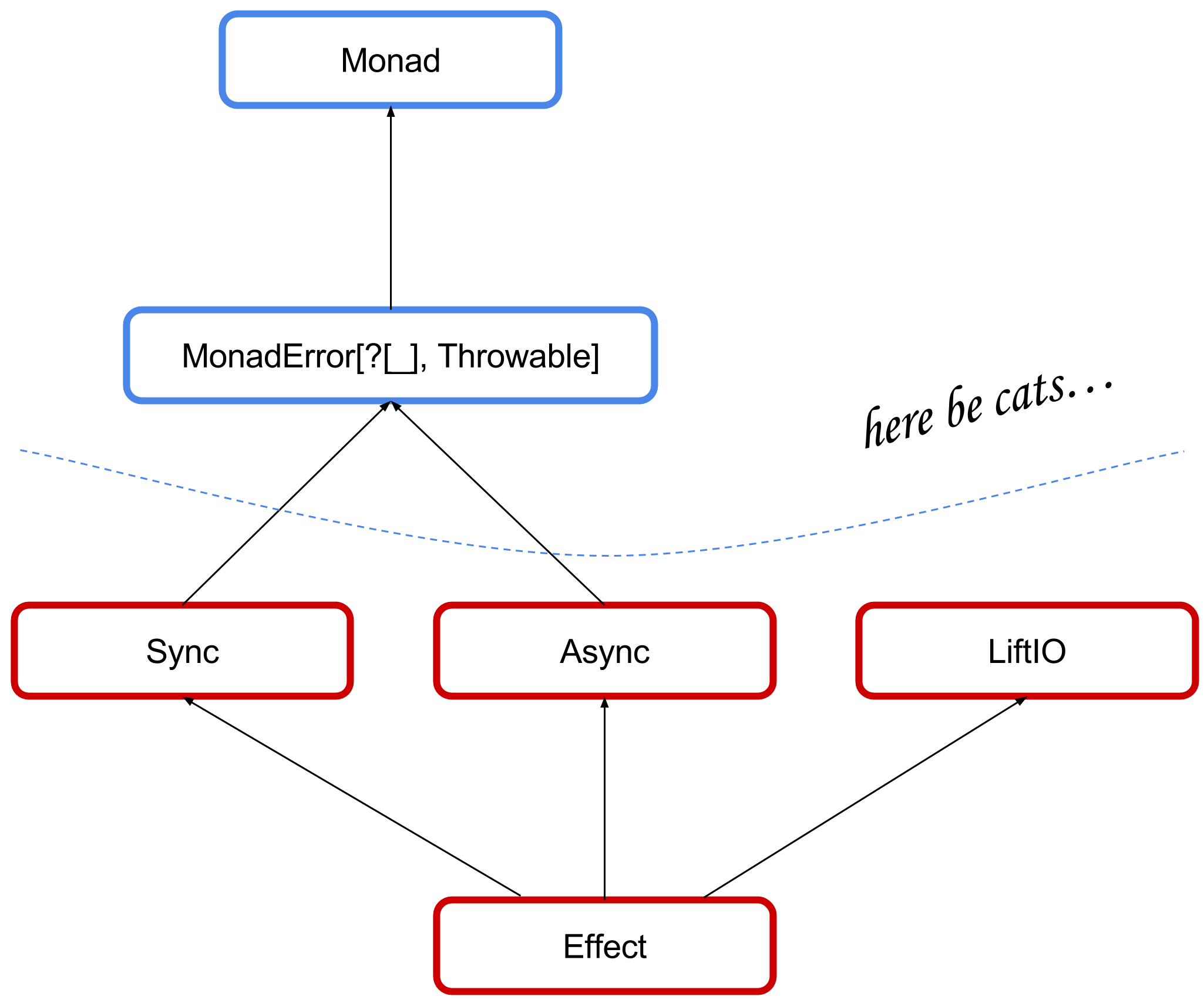
Monad and MonadError are of course a part of cats-core, while everything else is in cats-effect. MonadError is functionally equivalent to the familiar scalaz.Catchable typeclass, which was commonly used in conjunction with scalaz.concurrent.Task. It literally means “a monad with error-handling capabilities”. IO certainly fits that description, as any exceptions thrown within its apply method (or within async) will be caught and may be handled in pure code by means of the attempt function. Sync, Async, LiftIO and Effect are the new typeclasses.
Sync simply describes the IO.apply function (in the typeclasses, this function is called delay). Which is to say, any type constructor F[_] which has a Sync[F] has the capability to suspend synchronous side-effecting code. Async is very similar to this in that it describes the async function. So any type constructor F[_] which has an Async[F] can suspend asynchronous side-effecting code. LiftIO should be familiar to Haskell veterans, and is broadly useful for defining parametric signatures and composing monad transformer stacks.
Effect is where everything is brought together. In addition to being able to suspend synchronous and asynchronous side-effecting code, anything that has an Effect instance may also be asynchronously interpreted into an IO. The way this is specified is using the runAsync function:
import cats.effect.{Async, LiftIO, Sync}
trait Effect[F[_]] extends Sync[F] with Async[F] with LiftIO[F] {
def runAsync[A](fa: F[A])(cb: Either[Throwable, A] => IO[Unit]): IO[Unit]
}
What this is saying is that any Effect must define the ability to evaluate as a side-effect, but of course, we don’t want to have side-effects in our pure and reasonable code. So how are side-effects purely represented? With IO!
From a parametric reasoning standpoint, IO means “here be effects”, and so any type signature which involves IO thus also involves side-effects (well, effects anyway), and any type signature which requires side-effects must also involve IO. This bit of trickery allows us to reason about Effect in a way that would have been much harder if we had defined unsafeRunAsync as a member, and it ensures that downstream projects which write code abstracting over Effect types can do so without using any unsafe functions if they so choose (especially when taken together with the liftIO function).
Conclusion
The lack of a production-ready Task-like type fully integrated into the cats ecosystem has been a sticking point for a lot of people considering adopting cats. With the introduction of cats-effect, this should no longer be a problem! As of right now, the only releases are snapshots with hash-based versions, the latest of which can be found in the maven badge at the top of the readme. These snapshots are stable versions (in the repeatable-build sense), but they should not be considered stable, production-ready, future-proof software. We are quickly moving towards a final 0.1 release, which will depend on cats-core and will represent the stable, finalized API.
Once cats releases a final 1.0 version, cats-effect will also release version 1.0 which will depend on the corresponding version of cats-core. Changes to cats-effect are expected to be extremely rare, and thus the dependency should be considered quite stable for the purposes of upstream compatibility. Nevertheless, the release and versioning cycle is decoupled from cats-core to account for the possibility that breaking changes may need to be made independent of the cats-core release cycle.
Check out the sources! Check out the documentation. Play around with the snapshots, and let us know what you think! Now is the time to make your opinion heard. If IO in its current form doesn’t meet your needs, we want to hear about it!
