Library API
Laika's API is fully referentially transparent, does not throw exceptions and avoids any kind of runtime reflection. Its core module is also available for Scala.js. The library only has a very limited number of dependencies and does not require the installation of any external tools.
This chapter only covers the topics which are specific to using Laika without its sbt plugin, while most other parts of the manual apply to both use cases, library and plugin.
Dependencies
Which of the modules you need to add to the build depends on the functionality you intend to use.
If you want to stick to pure transformations from string to string and don't need file or stream IO or
any of the binary output formats like EPUB or PDF, you are fine with just using the laika-core module:
libraryDependencies += "org.typelevel" %% "laika-core" % "1.3.2" This module is also 100% supported for Scala.js, so you can alternatively use the triple %%% syntax
if you want to cross-build for Scala.js and the JVM:
libraryDependencies += "org.typelevel" %%% "laika-core" % "1.3.2" If you want to add support for file and stream IO and/or output in the EPUB format,
you need to depend on the laika-io module instead:
libraryDependencies += "org.typelevel" %% "laika-io" % "1.3.2" This depends on laika-core in turn, so you always only need to add one module as a dependency and will get
the rest via transitive dependencies. No module apart from laika-core is available for Scala.js, so you
are in JVM land here.
Finally PDF support comes with its own module as it adds a whole range of additional dependencies:
libraryDependencies += "org.typelevel" %% "laika-pdf" % "1.3.2" Again, this builds on top of the other modules, so adding just this one dependency is sufficient.
Anatomy of the API
The library API for creating parsers, renderers or transformers, while aiming to be intuitive and simple, also exposes one of the main design goals of Laika: that everything is meant to be pluggable.
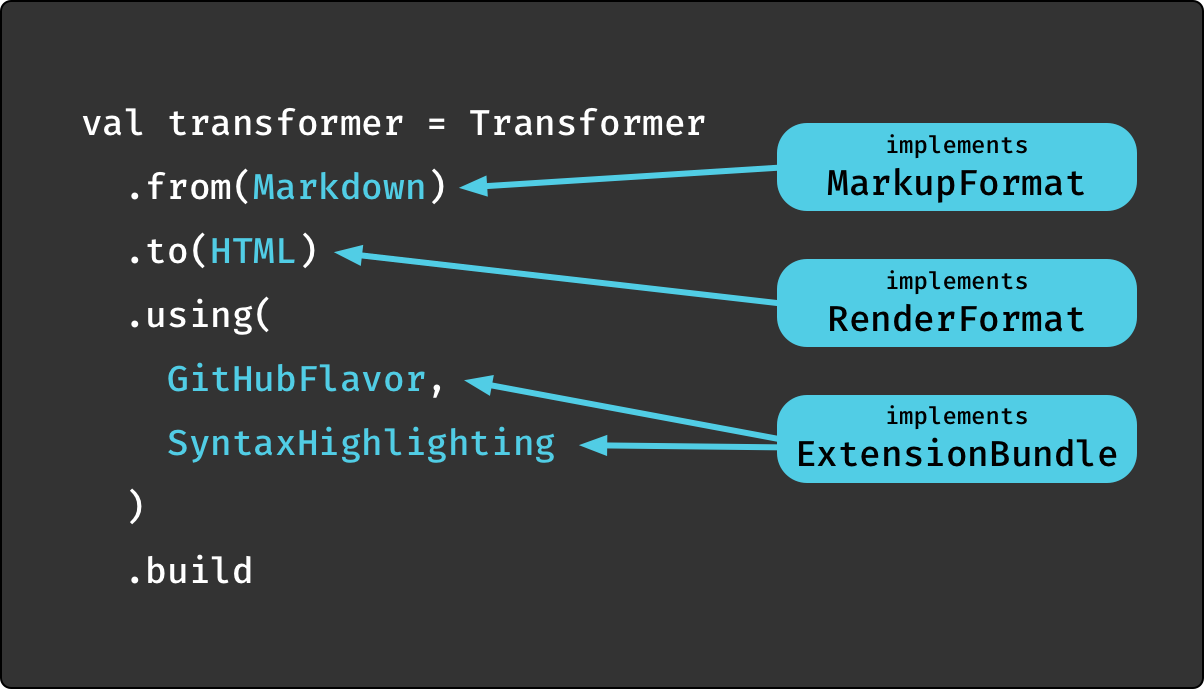
The following example for creating a pure transformer shows the main building blocks:
-
All inputs need to support the
MarkupFormatcontract. Supported by the core library areMarkdownandReStructuredText. -
Output formats implement the
RenderFormat[FMT]trait. The type parameter represents the formatter API that renderer overrides for specific AST nodes can talk to, which is different depending on the format. The library supports the formatsHTML,EPUB,PDF,XSLFOandASTout of the box. The latter is a debug output that renders the document AST in a formatted structure. -
Finally, the optional
usinghook in the API accepts anything that implementsExtensionBundle. This API has hooks for all phases of the transformation process, parsing, AST transformation and rendering and is Laika's main extension point. Shown above areGitHubFlavorandSyntaxHighlighting, two bundles provided by the library that can be enabled on demand.
If you require support for file/stream IO, templating or binary output formats,
the laika-io module expands on the core API to add this functionality:
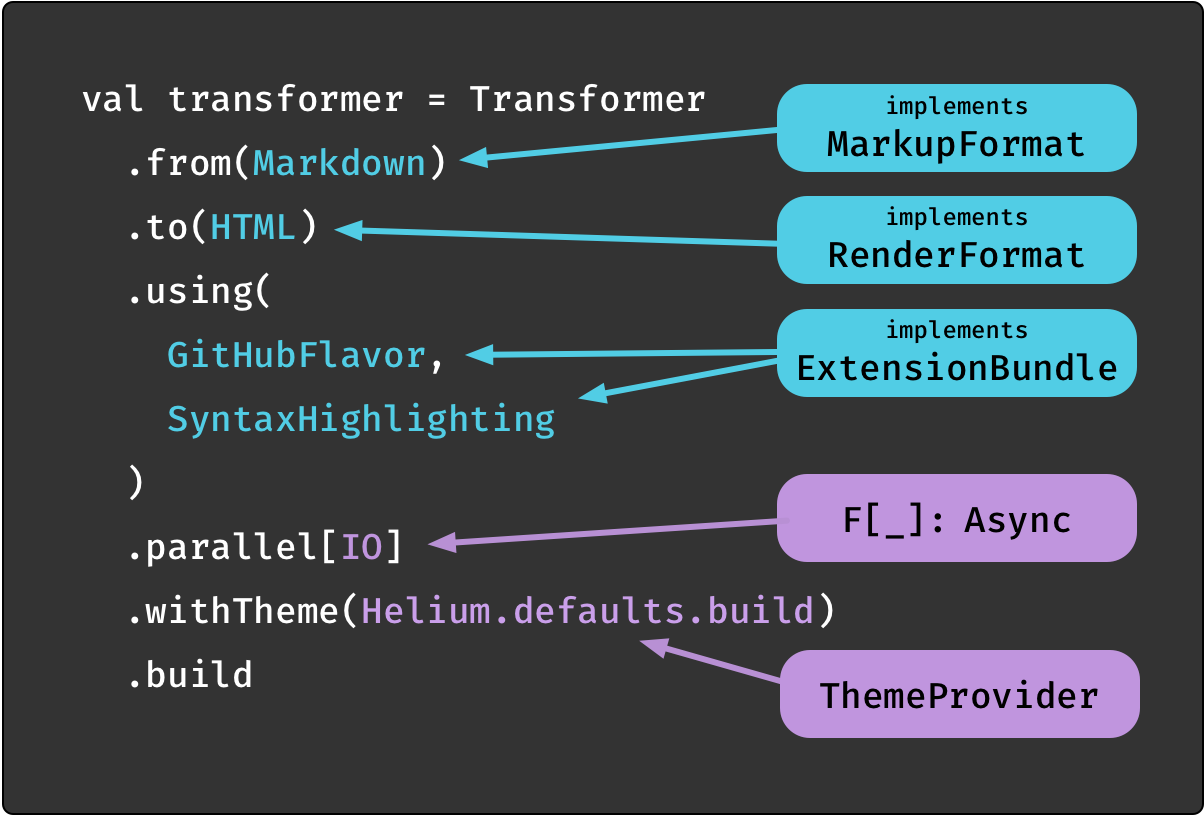
The blue elements of the API are identical to the pure transformer.
The new parallel method used above becomes available with import laika.io.syntax._.
This API introduces a dependency on cats-effect which is used to model the effectful computations.
You can use it with any effect that supports the cats-effect type classes, such as cats.effect.IO.
The call to parallel[IO] builds a transformer that lets you specify entire directories as input and allows to instruct
the library which effect type to use (cats-IO in this example). There are two more variants, sequential,
that processes inputs sequentially as well as an overload for parallel that allows to specify the level of parallelism.
Using a Transformer is the most convenient option when you want to go directly from the raw input format (text markup)
to the final output format. There are also Parser and Renderer instances that only do one half of the transformation.
All types, Transformer, Parser and Renderer come in two flavors each.
A simple, pure API for dealing with strings as input and output
and a parallel, effectful API for processing entire directories with templates and configuration files
in addition to the usual text markup input.
Transforming Strings
Transforming in-memory input is the simplest form of transformation, and works for Markdown and reStructuredText as input, and for HTML as output. EPUB and PDF both require additional modules and are described later in this chapter.
For most cases where you don't use any of the customization hooks, you should be fine with just these imports:
import laika.api._
import laika.format._As the next step you can then create transformer instances, which in most cases you'll want to reuse with different inputs to reduce the memory footprint and initialization overhead. The instances are immutable and thread-safe.
Example for creating a transformer for Markdown, including the GitHub-Flavor extensions:
val transformer = Transformer
.from(Markdown)
.to(HTML)
.using(Markdown.GitHubFlavor)
.buildExample for creating a transformer for reStructuredText:
val rstTransformer = Transformer
.from(ReStructuredText)
.to(HTML)
.buildIn addition to specifying markup and output formats and extensions, there are many other customization options in the builder
step immediately before calling build. They are identical for the pure and IO parser and are summarized in the Configuration section.
Finally you can use the transformer with text markup as input:
val result = transformer.transform("hello *there*")
// result: Either[errors.TransformationError, String] = Right(
// "<p>hello <em>there</em></p>"
// )The result is of type Either[ParserError, String].
Setup for Effectful Transformations
In case you want to go beyond pure string transformations,
you need to switch your dependency to the laika-io module as shown in the Dependencies section.
This dependency will add file/stream IO, theme support, templating and the ability to process entire directories.
This module depends on cats-effect, and models all side effects in an abstract effect.
With the dependency in place you also need to add a third import to those you used for pure transformations:
import laika.api._
import laika.format._
import laika.io.syntax._The remainder of the setup depends on whether you are Using cats-effect or whether you build Applications without Effect Library.
Using cats-effect
When your application is already using one of the libraries compatible with the cats-effect type class hierarchy, integrating Laika will be seamless.
The exact mechanics of your Laika transformer setup will depend on which of those libraries you are using
and whether you keep all of your code in an abstract F[_] instead of coding against a concrete effect type.
The following example assumes the use case of an application written around abstract effect types and using IOApp
from cats-effect for initialization:
import cats.effect.{ Async, Resource }
import laika.io.api.TreeTransformer
def createTransformer[F[_]: Async]: Resource[F, TreeTransformer[F]] =
Transformer
.from(Markdown)
.to(HTML)
.using(Markdown.GitHubFlavor)
.parallel[F]
.buildThe setup method above can then be used inside IOApp initialization logic:
import cats.effect.{ IO, IOApp, ExitCode }
object MyApp extends IOApp {
def run(args: List[String]) = {
createTransformer[IO].use { transformer =>
// create modules depending on transformer
IO.unit
}.as(ExitCode.Success)
}
}Setup for other libraries would be similar, Monix for example comes with a TaskApp which is similar to IOApp.
The Resource provided by Laika is meant to be initialized only once per application,
so that the initialization logic and the loading of themes from the jars does only execute once.
Applications without Effect Library
When using other stacks like Akka HTTP or the Play framework, you need to bridge the gap between the worlds of cats-effect and the surrounding toolkit, often centering around the Future API (which, in contrast to cats-effect, is not referentially transparent).
Assuming we reuse the createTransformer method from the previous section, you can then run a transformation
and obtain the resulting effect:
import laika.io.model.RenderedTreeRoot
val result: IO[RenderedTreeRoot[IO]] = createTransformer[IO].use {
_.fromDirectory("docs")
.toDirectory("target")
.transform
}The resulting IO instance is only a description of a program, as it starts evaluation lazily,
in contrast to the Scala SDK's Future which starts processing eagerly.
For actually running the effect and producing a result, you have several options depending on the stack you are using.
First, for any of the following options, you need to add the following import:
import cats.effect.unsafe.implicits.globalAlternatively you can manually construct an IORuntime if you need precise control over the ExecutionContext used
in your application.
One common scenario is a toolkit like Akka HTTP or Play where you execute a route that is expected to return a Future.
This can achieved by a simple translation:
import scala.concurrent.Future
val futureResult: Future[RenderedTreeRoot[IO]] = result.unsafeToFuture()Other options not involving Future are either blocking, synchronous execution:
val syncResult: RenderedTreeRoot[IO] = result.unsafeRunSync()Or asynchronous execution based on a callback:
def handleError(error: Throwable): Unit = ???
def handleResult(result: RenderedTreeRoot[IO]): Unit = ???
result.unsafeRunAsync {
case Left(throwable) => handleError(throwable)
case Right(result) => handleResult(result)
}Do not get too hung up on the scary sound of all these unsafe... methods. The one kind of safety you are losing
when using them is referential transparency. But if you are using a Future-based API for example,
your program is not referentially transparent anyway.
Finally, if you intend to reuse the transformer, for example in a web application based on the Play framework,
it is more efficient to split the resource allocation , use and release into three distinct effects that you can run
independently, as the sample IO above would re-create the transformer for each invocation:
val alloc = createTransformer[IO].allocated
val (transformer: TreeTransformer[IO], releaseF: IO[Unit]) = alloc.unsafeRunSync()You would usually run the above when initializing your web application.
The obtained transformer can then be used in your controllers and each transformation would produce a new Future:
val futureResult: Future[RenderedTreeRoot[IO]] = transformer
.fromDirectory("docs")
.toDirectory("target")
.transform
.unsafeToFuture()In this case you also need to ensure you run the release function on shutdown:
releaseF.unsafeRunSync()The default Helium theme currently has a no-op release function, but this might change in the future and 3rd-party themes might behave differently, too. Therefore, it is good practice to ensure that the release function is always run.
When using an application based on cats-effect, the Resource type safely deals with this, but when integrating
with impure environments, these extra manual steps are necessary.
Entire Directories as Input
The effectful transformer is the most powerful variant and also the one that is the basis for the sbt plugin. It expands the functionality beyond just processing markup input to also parsing templates and configuration files as well as copying static files over to the target directory.
val transformerIO = Transformer
.from(Markdown)
.to(HTML)
.using(Markdown.GitHubFlavor)
.parallel[IO]
.buildThe above transformer can then be used to process a directory of markup, template and configuration files:
val res: IO[RenderedTreeRoot[IO]] = transformerIO.use {
_.fromDirectory("src")
.toDirectory("target")
.transform
}The target directory is expected to exist, while any required subdirectories will be automatically created during rendering.
There will be one HTML file for each input file in the same directory layout.
If you replace the HTML renderer in the example above with one of the binary formats (EPUB or PDF),
the API will be slightly different, as the toDirectory option is replaced by toFile.
This is because these formats always produce a single binary result,
merging all content from the input directories into a single, linearized e-book:
val epubTransformer = Transformer
.from(Markdown)
.to(EPUB)
.using(Markdown.GitHubFlavor)
.parallel[IO]
.build
val epubRes: IO[Unit] = epubTransformer.use {
_.fromDirectory("src")
.toFile("output.epub")
.transform
}Merging Multiple Directories
All previous examples read content from the single input directory. But you can also merge the contents of multiple directories:
import laika.io.model.FilePath
val directories = Seq(
FilePath.parse("markup"),
FilePath.parse("theme")
)
val mergedRes: IO[RenderedTreeRoot[IO]] = transformerIO.use {
_.fromDirectories(directories)
.toDirectory("target")
.transform
}This adds some additional flexibility, as it allows, for example, to keep reusable styles and templates separately. This flexibility is possible as Laika is not tied to the file system, but instead provides a Virtual Tree Abstraction.
Freely Composing Inputs
If you need even more flexibility instead of just configuring one or more input directories,
e.g. when there is a need to generate content on-the-fly before starting the transformation,
you can use the InputTree builder.
import laika.io.model._
import laika.ast.DefaultTemplatePath
import laika.ast.Path.Root
def generateStyles: String = "???"
val inputs = InputTree[IO]
.addDirectory("/path-to-my/markup-files")
.addDirectory("/path-to-my/images", Root / "images")
.addClassResource("templates/default.html", DefaultTemplatePath.forHTML)
.addString(generateStyles, Root / "css" / "site.css")In the example above we specify two directories, a classpath resource and a string containing CSS generated on the fly. By default directories get merged into a single virtual root, but in the example we declare a mount point for the second directory, which causes the content of that directory to be assigned the corresponding logical path.
Always keep in mind that declaring inputs and outputs are the only places in the Laika universe where you'd ever use concrete file system paths. Beyond this configuration step you are entirely within Laika's virtual path abstraction and refer to other resources by their virtual path. This is true for linking, using image resources, specifying templates to use in configuration headers, and so on. It means that everything you can refer to in your markup files needs to be included in the input composition step.
The InputTreeBuilder API gives you the following options:
-
Add entire directories and optionally specify a "mount point" at which they should be linked in the virtual tree.
-
Specify individual files or classpath resources.
-
Add in-memory strings which will enter the parsing pipelines like file resources.
-
Add in-memory AST nodes which will by-pass the parsing step and will be added directly to the other document AST obtained through parsing.
When generating input on the fly it is usually a question of convenience or reducing boilerplate whether you choose to generate a string for parsing or the AST directly.
For the complete API see InputTreeBuilder.
The customized input tree can then be passed to the transformer:
val composedRes: IO[RenderedTreeRoot[IO]] = transformerIO.use {
_.fromInput(inputs)
.toDirectory("target")
.transform
}Preparing Content
Laika does not have any special directories and content can be nested in sub-directories down to arbitrary levels. For more details on how to organize content, see Directory Structure.
Transformers and Parsers distinguish between the following file types:
- Markup Files: Files with the extensions
.md,.markdownor.rst(depending on the specified input format) will be parsed and rendered to the target in the same directory structure and with the same file names apart from the suffix, which will be replaced depending on the output format (e.g..html). - Configuration Files: Each directory can contain an optional
directory.conffile for specifying things like navigation order or chapter title. See Configuration Files for details. - Template Files: You can provide a default template per directory with the name
default.template.<suffix>with the suffix matching the output format (e.g..html). They will also be applied to sub-directories, unless overridden. Default templates in one of your input directories always override default templates provided by themes. You can also add additional templates with the name pattern*.template.<suffix>, which will only be applied when a markup document explicitly refers to them in its configuration header. - Static Files: All other files, like CSS, JavaScript, images, etc., will be copied over to the target in the same directory structure and with identical file names.
Separate Parsing and Rendering
So far all examples in this chapter showed the use of a transformer instance, which takes you all the way from a raw input file to the target format, e.g. from Markdown to HTML.
But in some cases you may just want to execute one half of the process:
-
If the input is generated in-memory. In this case there is no need to generate text markup, you can directly produce the document AST and pass it to a
Renderer. -
If you want to process the document AST produced by a
Parserby other means than rendering one of the supported output formats. -
If you want to render the same input to multiple output formats. In this case building a
Transformerfor all output formats is inefficient as each of them would parse the same input again. Instead you can create a singleParserfor the input and in addition oneRendererfor each output format you want to generate.
In fact if you examine the implementations of the various pure and effectful transformer types, you'll notice that
it is mostly trivial: delegating to the underlying Parser and Renderer and just piping the result from one to the other.
The following code example demonstrates the third scenario listed above: Rendering the same input to multiple output formats.
First we set up a parser and its configuration. We create a parallel parser that is capable of reading from a directory:
val parserBuilder = MarkupParser.of(Markdown).using(Markdown.GitHubFlavor)
val parser = parserBuilder.parallel[IO].build
val config = parserBuilder.configNext we create the renderers for the three output formats:
val htmlRenderer = Renderer.of(HTML).withConfig(config).parallel[IO].build
val epubRenderer = Renderer.of(EPUB).withConfig(config).parallel[IO].build
val pdfRenderer = Renderer.of(PDF).withConfig(config).parallel[IO].buildNotice that we pass the config value obtained from the parser to all renderers.
First, this simplifies the code as any custom configuration you define for the parser
will be automatically shared, and secondly, it ensures that any extensions added
by the parser itself are known to the renderers.
Since all four processors are a cats-effect Resource, we combine them into one:
val allResources = for {
parse <- parser
html <- htmlRenderer
epub <- epubRenderer
pdf <- pdfRenderer
} yield (parse, html, epub, pdf)Finally, we define the actual transformation by wiring the parser and the three renderers:
import cats.syntax.all._
val transformOp: IO[Unit] = allResources.use {
case (parser, htmlRenderer, epubRenderer, pdfRenderer) =>
parser.fromDirectory("source").parse.flatMap { tree =>
val htmlOp = htmlRenderer.from(tree.root).toDirectory("target").render
val epubOp = epubRenderer.from(tree.root).toFile("out.epub").render
val pdfOp = pdfRenderer.from(tree.root).toFile("out.pdf").render
(htmlOp, epubOp, pdfOp).parMapN { (_, _, _) => () }
}
}We are using cats' parMapN here to run the three renderers in parallel.
The tree instance passed to all renderers is of type DocumentTreeRoot.
If necessary you can use its API to inspect or transform the tree before rendering.
See The Document AST for details.
Our little sample setup will run with the Helium theme and all its defaults applied. In the (very common) case that you customize the theme (colors, fonts, landing page content, etc.), you need to pass it to all parsers and renderers.
import laika.helium.Helium
val helium = Helium.defaults
.site.baseURL("https://foo.com")
.build
val customParser = parserBuilder
.parallel[IO]
.withTheme(helium)
.build
val customHTML = Renderer
.of(HTML)
.withConfig(config)
.parallel[IO]
.withTheme(helium)
.build
// ... repeat for all other renderersThe sample code in this scenario showed the effectful variant of the Parser and Renderer types,
but just as the Transformer they exist in the other flavor as well: a pure variant as part of the laika-core module.
Configuration
All the examples in this chapter only scratched the surface of Laika's API, focusing on the basics like specifying input and output. But since Laika is designed to be fully customizable and serve as a toolkit for creating toolkits, there is a whole range of options available for customizing and extending its built-in functionality.
Most of these configuration options are not specific to the library API use case and apply to the sbt plugin as well, apart from differences in the syntax/mechanics with which they are applied, which are reflected in the corresponding code examples. For this reason this section only gives a very brief overview while linking to the relevant sections in the other chapters.
Theme Configuration
Configuration for the built-in Helium theme or a 3rd-party theme can be passed to the transformer builders. You can also specify an empty theme if you want to put all templates and styles right into your input directory.
Example for applying a few Helium settings:
import laika.helium.Helium
val theme = Helium.defaults
.all.metadata(
title = Some("Project Name"),
language = Some("de"),
)
.epub.navigationDepth(4)
.pdf.navigationDepth(4)
.build
val heliumTransformer = Transformer
.from(Markdown)
.to(HTML)
.using(Markdown.GitHubFlavor)
.parallel[IO]
.withTheme(theme)
.buildIf you do not explicitly pass a theme configuration Laika will run with the default settings of the Helium theme, meaning your site and e-books will look exactly like this documentation, including all color and font choices.
Since the default Helium theme offers a lot of configuration options it has its own dedicated chapter Theme Settings. They are specific to the Helium theme, when using a 3rd-party theme you need to consult their documentation for setup options.
To just give a brief overview, those settings allow you to configure:
-
The Fonts to embed in EPUB and PDF files or to link in HTML files.
-
The Colors for the main theme and for syntax highlighting.
-
Several aspects of the theme's Layout, like column widths, block spacing or PDF page sizes.
-
Metadata (title, authors, description, language, etc.) to include in the generated site or e-books.
-
Adding Favicons or custom links to the Top Navigation Bar
-
Adding an optional Download Page for the site's content as EPUB or PDF
-
Providing logos, text and links for an optional Website Landing Page.
-
Configure Cover Images for E-books or Auto-Linking CSS & JS Files.
Other Settings
These other settings are available independent from the theme in use:
-
Strict mode: Disables all non-standard extensions Laika adds to the supported markup formats, like directives.
-
Raw Content: Enables the inclusion of raw sections of the target format in markup files, e.g. snippets of verbatim HTML embedded in Markdown files. By default this is disabled.
-
Character Encoding: Sets the character encoding of input and output files, the default is UTF-8.
-
Error Handling: Specify log levels or switch to "visual debugging", where recoverable errors are rendered in the page context where they occur instead of causing the transformation to fail.
-
Laika Extensions: Use the library's customization options to override renderers for specific AST nodes (Overriding Renderers), transform the document AST before rendering (AST Rewriting), install custom directives (Implementing Directives) or use some of the lower level hooks in (The ExtensionBundle API).
-
Basic Configuration Options: setting the Character Encoding, controlling Error Handling and specifying User-Defined Variables.
-
Inspecting Laika's Configuration: Run the
describemethod on the IO-based transformers, parsers and renderers to get a formatted summary of the active configuration, installed extension bundles and lists of input and output files.
Using the Preview Server
Laika contains a preview server that can be used to browse generated sites.
This includes auto-refreshing whenever changes to any input document are detected.
It is the basis of the laikaPreview task of the sbt plugin,
but can alternatively be launched via the library API:
import laika.preview.ServerBuilder
val parser = MarkupParser
.of(Markdown)
.using(Markdown.GitHubFlavor)
.parallel[IO]
.build
val inputs = InputTree[IO]
.addDirectory("/path/to/your/inputs")
ServerBuilder[IO](parser, inputs)
.build
.use(_ => IO.never)The above example creates a server based on its default configuration.
Open localhost:4242 for the landing page of your site.
You can override the defaults by passing a ServerConfig instance explicitly:
import laika.preview.ServerBuilder
import laika.preview.ServerConfig
import com.comcast.ip4s._
import scala.concurrent.duration.DurationInt
val serverConfig =
ServerConfig.defaults
.withPort(port"8080")
.withPollInterval(5.seconds)
.withEPUBDownloads
.withPDFDownloads
.verbose
ServerBuilder[IO](parser, inputs)
.withConfig(serverConfig)
.build
.use(_ => IO.never)By default, the port is 4242, the poll interval is 3 seconds, and EPUB or PDF downloads will not be included in the generated site.
Preview of the Document AST
Introduced in version 0.19.4 the preview server can now also render the document AST for any markup source document.
Simply append the /ast path element to your URL, e.g. localhost:4242/my-docs/intro.html/ast.
Note that this does not prevent you from using /ast as an actual path segment in your site,
the server will be able to distinguish those.
The AST shown is equivalent to the AST passed to the actual renderer after the final rewrite phase. In case of writing custom render overrides it is the most accurate representation of the nodes you can match on. When writing rewrite rules for earlier phases the actual nodes to match on might differ (e.g. directives and links might still be unresolved).