New Markup or Output Formats
All the other chapters in the "Extending Laika" section of the manual deal with a customization option
that at some point becomes part of an ExtensionBundle.
As Anatomy of the API showed, it is one of the major API hooks for building a transformer:
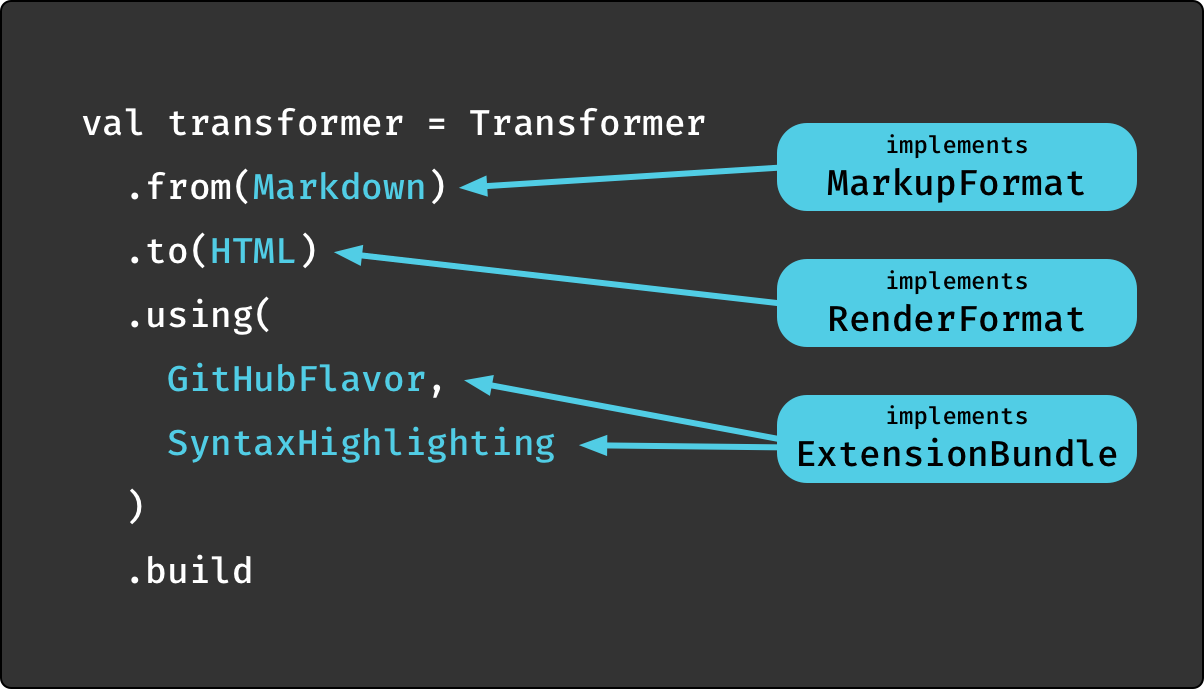
While an ExtensionBundle is about enhancing functionality for existing input and output formats,
this chapter finally is about actually adding new formats.
Therefore it deals with the other two types in the diagram: MarkupFormat and RenderFormat[FMT].
Implementing a Markup Format
Laika currently supports two markup formats out of the box: Markdown and reStructuredText. Having two formats from the beginning greatly helped in shaping a document model that is not tied to the specifics of a particular text markup language.
Making it as straightforward as possible to add support for more formats like ASCIIDoc or Textile was one of Laika's initial design goals.
Parser Prerequisites
The content of this chapter builds on top of concepts introduced in other chapters, therefore it's recommended to read those first.
First, all parsers build on top of Laika's Parser Combinators. Having its own implementation helps with keeping all functionality tightly integrated and adding some optimizations useful for the specific use case of markup parsing right into the base parsers.
Second, since block and span parsers that together provide the markup implementation all produce AST nodes, it might help to get familiar with The Document AST first.
Finally, Writing Parser Extensions covers a lot of ground relevant for adding a new format, too. It walks through the sample implementation of a span parser.
The main difference is merely that a block or span parser serving as an extension for existing markup languages
will be registered with an ExtensionBundle,
while the parsers for a new format need to be registered in a MarkupFormat.
The MarkupFormat Trait
The contract a markup implementation has to adhere to is captured in the following trait:
import laika.api.bundle.{ BlockParserBuilder, ExtensionBundle, SpanParserBuilder }
import laika.api.format.MarkupFormat.MarkupParsers
trait MarkupFormat {
def fileSuffixes: Set[String]
def blockParsers: MarkupParsers[BlockParserBuilder]
def spanParsers: MarkupParsers[SpanParserBuilder]
def extensions: Seq[ExtensionBundle]
}These are the four abstract methods each parser has to implement.
-
The
fileSuffixesmethod should simply return the set of supported file suffixes (without the '.'). For Markdown this would beSet("md", "markdown")for example. It is not recommended to support generic suffixes liketxtas this could lead to conflicts with other parsers.Laika supports a setup where input directories may contain source files written in different markup languages. In this case the format detection is solely based on the file suffix.
-
The
blockParsersandspanParsersproperties provide the definitions for the actual markup parsers. These are the same types you've already seen when registering parsers as extensions.Builtin parsers implement these two properties in a way that they also expose the individual top-level parsers via its API so that users can alternatively cherry-pick them and compose them with other parsers for their own extensions or custom formats.
It may sound too good to be true, but the task of assembling the building blocks of a markup language in Laika is indeed merely declarative. The parsers for individual elements like lists or links can almost always be implemented in isolation with little or no interdependencies.
Writing Parser Extensions contains a walk-through of a span parser implementation. You can also browse the code for Laika's Markdown and reStructuredText support for more examples.
-
The
extensionscollection allows to add functionality beyond just markup parsing. It uses the sameExtensionBundletrait that exists for users to customize a transformation.Whenever a format that defines extensions is used, they are merged with the user-supplied extensions. This collection may very well remain empty for some formats.
Finally, there are three concrete methods that may be overridden if required:
def description: String = toString
def escapedChar: Parser[String] = TextParsers.oneChar
def createBlockListParser (parser: Parser[Block]): Parser[Seq[Block]] =
(parser <~ opt(blankLines)).rep-
The
descriptionmethod allows to add details for tooling and logging. -
The
escapedCharmethod controls the parsing of an escape sequence (the character after a backslash). The default implementation accepts any character. -
Finally,
createBlockListParsercontrols how a parser for a single block is turned into a parser for a sequence of blocks. The default implementation just skips blank lines between the blocks and repeats the same parser. The parser passed to this method already includes all the (merged) block parsers this trait has specified as well as any extensions a user might have installed.
Parser Precedence
The parser precedence is determined by the order you specify them in. This means they will be "tried" on input in that exact order. The second parser in the list will only be invoked on a particular input when the first fails, and so on.
This is the logical execution model only, the exact runtime behaviour may differ due to performance optimizations, but without breaking the guarantees of respecting the order you specify.
Normally the difference in the syntax between markup constructs is high enough that the precedence does not matter.
But in some cases extra care is needed.
If, for example, you provide parsers for spans between double asterisk ** and between single asterisk *,
the former must be specified first, as otherwise the single asterisk parser would 100% shadow the double one
and consume all matching input itself, unless it contains a guard against it.
Implementing a Render Format
Laika currently supports several output formats out of the box: HTML, EPUB, PDF, XSL-FO and AST. XSL-FO mostly serves as an interim format for PDF output, but can also be used as the final target format. AST is a renderer that provides a formatted output of the document AST for debugging purposes.
Making it as straightforward as possible to add support for additional output formats, potentially as a 3rd-party library, was one of Laika's initial design goals.
Renderer Prerequisites
The content of this chapter builds on top of concepts introduced in other chapters, therefore it's recommended to read those first.
First, since renderers have to pattern match on AST nodes the engine passes over, it might help to get familiar with The Document AST first.
Second, Overriding Renderers shows examples for how to override the renderer of a particular output format for one or more specific AST node types only.
The main difference is that a renderer serving as an override for existing output formats
will be registered with an ExtensionBundle,
while the renderers for a new format need to be registered in a RenderFormat.
The second difference is that a RenderFormat naturally has to deal with all potential AST nodes,
not just a subset like an override.
The RenderFormat Trait
A renderer has to implement the following trait:
import laika.ast.Element
import laika.api.format.Formatter
trait RenderFormat[FMT] {
def fileSuffix: String
def defaultRenderer: (FMT, Element) => String
def formatterFactory: Formatter.Context[FMT] => FMT
}-
The
fileSuffixmethod provides the suffix to append when writing files in this format (without the "."). -
The
defaultRendererrepresents the actual renderer. It takes both, a formatter instance and the element to render and returns a String in the target format. -
formatterFactoryis the formatter instance for the target format. A new instance of this formatter gets created for each render operation. -
The
Formatter.Contextpassed to the factory function contains the root element of the AST and the delegate render function which your formatter is supposed to use for rendering children. You need to use this indirection as the provided delegate contains the render overrides the user might have installed which your default render implementation cannot be aware of. -
FMTis a type parameter representing the Formatter API specific to the output format. For the built-in renderers, this isTagFormatterforPDF,HTMLandEPUBandFormatterfor theASTrenderer.
The Render Function
This defaultRenderer function should usually adhere to these rules:
-
When given an element that is a container type that contains child elements (like
ParagraphorBulletList), it should never render the children itself, but instead delegate to the Formatter API, so that user-defined render overrides can kick in for individual element types. -
It should expect unknown element types. Since parsers can also be extended, the document tree can contain nodes which are not part of the default node types provided by Laika. The root trait
Elementis not sealed on purpose.Dealing with unknown types is best achieved by not only matching on concrete types, but also on some of the base traits.
If, for example, you already handled all the known
SpanContainers, likeParagraph,HeaderorCodeBlock, you would ideally add a fallback pattern that matches on anySpanContainerand provides a default fallback. This way, even though you don't know how to best render this particular container, at least all its children will most likely get rendered correctly.As an absolute worst-case fallback it should add a catch-all pattern that returns an empty string.
Let's look at a minimal excerpt of a hypothetical HTML render function:
import laika.ast._
import laika.api.format.TagFormatter
def renderElement (fmt: TagFormatter, elem: Element): String = {
elem match {
case p: Paragraph => fmt.element("p", p)
case e: Emphasized => fmt.element("em", e)
/* [other cases ...] */
/* [fallbacks for unknown elements] */
}
}As you see, the function never deals with children (the content attribute of many node types) directly.
Instead it passes them to the Formatter API which delegates to the composed render function.
This way user-specified render overrides can kick in on every step of the recursion.
In the context of HTML it means that in most cases your implementation renders one tag only before delegating,
in the example above those are <p> and <em> tags respectively.
Choosing a Formatter API
Depending on the target format your renderer may use the Formatter or TagFormatter APIs,
which are explained in The Formatter APIs.
Alternatively it may create its own API, but you should keep in mind then, that this API will also get used by users overriding renderers for specific nodes. Therefore, it should be convenient and straightforward to use and well documented (e.g. full scaladoc).
Even when creating your own formatter it's probably most convenient to at least extend Formatter,
which contains base logic for indentation and delegating to child renderers.
Costs of Avoiding Side Effects
As you have seen the render function returns a String value, which the engine will then build up
recursively to represent the final output.
It can therefore get implemented as a pure function, fully referentially transparent.
Earlier Laika releases had a different API which was side-effecting and returning Unit. Renderers directly wrote to the output stream, only hidden behind a generic, side-effecting delegate API.
Version 0.12 in 2019 then introduced full referential transparency and one of the necessary changes was the change of the render function signature. These changes (taken together, not specifically that for the Render API) caused a performance drop of roughly 10%. It felt reasonable to accept this cost given how much it cleaned up the API and how it lifted the library to meet expectations of developers who prefer a purely functional programming style.
The decent performance of Laika stems mostly from a few radical optimizations on the parser side, which led to much better performance compared to some older combinator-based Markdown parsers.
The alternative would have been to build on top of a functional streaming API like fs2,
as this might have preserved both, the old performance characteristics as well as full referential transparency.
But it still would have complicated the API and introduced a dependency that is not needed anywhere
else in the laika-core module, which does not even require cats-effect.